
Quella delle duplicazioni di contenuti è una delle problematiche che affligge molti webmaster e spesso viene sottovalutata anche da molti seo o, peggio ancora, spesso non se ne conosce nemmeno l’esistenza. Ho visto diversi e-commerce costruiti anche piuttosto bene e con un buon aspetto grafico che poi andavano a scontrarsi con numero imprecisato di urls che a tutti gli effetti identificavano pagine identiche ma che differivano soltanto nell’aspetto della url.
Negli e-commerce il problema si presenta con maggiore frequenza di quanto si possa credere, principalmente a causa dell’architettura con cui l’e-commerce è costruito, che permette ad esempio di ordinare i prodotti per filtri di ricerca per prezzo, taglia, quantità, ecc. e quindi permettere a diverse pagine di essere accessibile da diverse urls.
Le url duplicate, oltre a non aggiungere alcun valore all’utente non forniscono neanche alcun valore ai bot, anzi, diminuiscono quello che viene chiamato “crawl budget” del sito, ma fanno anche sì che il pagerank e il tema del sito venga diluito su più urls che non hanno valore, quando invece potrebbe essere consolidato sulle url di quelle pagine da noi identificate come essere quelle canoniche e che vogliamo far rankare nelle serp. Una grande serie di url duplicate internamente, potrebbero inoltre dare al sito web problemi legati a possibilità di cadere in filtri come Panda.
Come individuare la presenza di url duplicati
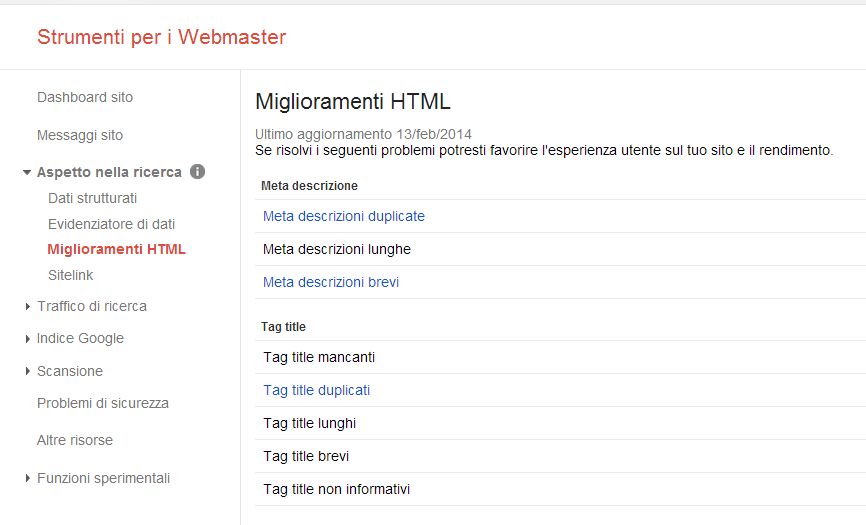
Un primo e semplice metodo è quello di andare a visualizzare, nel Google WebMaster Tools la presenza di tag title e meta descrizioni duplicate. Generalmente una url duplicata avrà anche un title tag e una descrizione duplicata. Andando nella sezione “Aspetto nella ricerca > Miglioramenti HTML”, troverete il numero di titoli e descrizioni che bisognerà poi verificare se siano state o meno indicizzate oppure filtrate in modo automatico da Google o se necessitano di interventi in termini di canonicalizzazione o di blocco nel robots.txt o con un meta noindex.
Un altro metodo molto utile consiste nell’utilizzare il site: command di Google per rilevare la presenza di url duplicate e presenti nell’indice. Se volete ad esempio verificare la presenza di url che duplicano la homepage e che riportano lo stesso title tag, andrà utilizzato il seguente comando:
site:ilmiosito.it intitle:”titolo della homepage”, escludendo il www.

Se invece gestite un e-commerce e volete ad esempio identificare la presenza di urls duplicate dall’esistenza di filtri di ordinamento, potete cercare col site command l’esistenza delle urls sulla base del parametro che l’e-commerce utilizza per filtrare i prodotti. Se ad esempio il parametro è “sort” la ricerca apparirà come segue.

Tipologie di duplicazioni contenutistiche
Vediamo ora alcune tipologie di duplicazioni interne in cui possiamo imbatterci, sebbene questa lista non sarà esaustiva.
1. WWW e NON-WWW
La prima e forse più nota e spesso sottovalutata, è quella dovuta alla presenza della versione www e non-www del sito. Se non è settato il redirect sulla reale versione del sito, eventuali links acquisiti alla versione errata andranno del tutto persi. Si può risolvere il problema impostando un Redirect 301 sulla versione preferita.
2. Slash finali nelle url (“/”)
Può capitare, di rilevare pagine che seppur identiche, differiscono tra di loro per la presenza di uno slash sul finale di una delle due urls. Ad esempio:
www.ilmiosito.com/prodotto1
www.ilmiosito.com/prodotto1/
In questa situazione la prima url rappresenterà una pagina e la seconda in realtà un folder (una cartella). Sebbene Google solitamente sia in grado di canonicalizzare automaticamente tali urls, se in serp rileviamo la presenza anche della url duplicata, potremo risolverla implementando un Redirect 301 sulla url e pagina canonica.
3. Pagine di sicurezza
Le pagine di sicurezza sono identificate dal protocollo https ma può accadere che vengano indicizzate, ad esempio quelle relative ai carrelli degli ecommerce. Il modo migliore per risolvere il problema è quello di bloccare l’accesso ai bot con un disallow nel robots.txt.
4. HomePage duplicate
Può capitare di trovarsi in situazioni che presentano la duplicazione della homepage, su url differenti ed avere ad esempio una situazione del genere:
www.ilmiosito.com
www.ilmiosito.com/index.htm
Solitamente il problema può essere risolto con Redirect 301 sulla versione canonica oppure, qualora non sia possibile effettuare un redirect, aggiungendo un rel=canonical sulla versione canonica. Questo però non deve poi scontrarsi col fatto che per qualche motivo facciamo linkare la versione non canonica nel sito, mandando quindi a Google segnali contrastanti (da un lato gli diciamo di considerarla canonica di una versione e dall’altro lato gli diciamo di seguirla). Attenzione quindi a strutturare una corretta architettura del sito.
5. Duplicati di pagine di ricerca dei filtri di navigazione
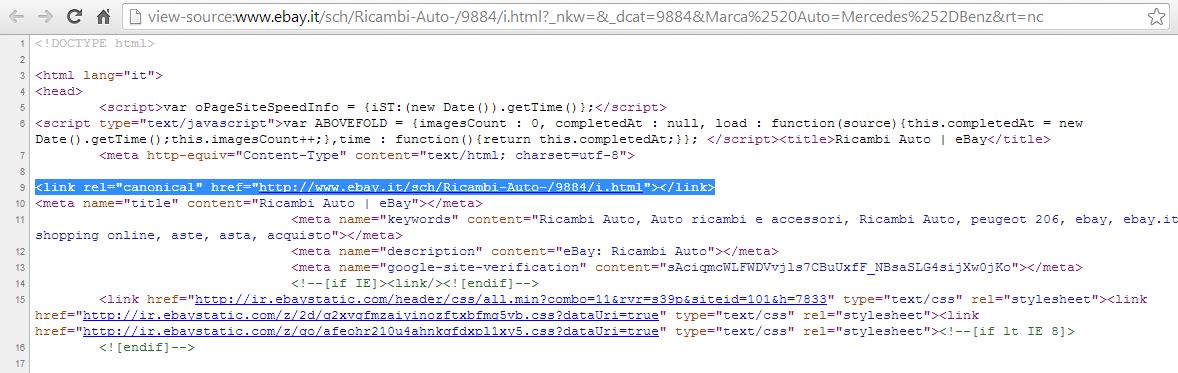
Per i portali e gli e-commerce che usano filtri di ordinamento come il prezzo, le url generate non sono altro che pagine utili agli utenti ma non ai bot, in quanto si trovano dinanzi agli stessi contenuti, stessi prodotti, già spiderizzati ma disposti in ordine leggermente diverso. In questo caso può essere utile bloccare i parametri del filtri di ricerca nel google webmaster tools, o dal robots.txt ma la soluzione migliore a mio avviso resta sempre quella di inserire un rel canonical sulla pagina preferita, come fa ad esempio Ebay.it che rimanda tutte le url generate da filtri di ordinamento alla url canonica della categoria di prodotto.
6. E se a duplicare i contenuti è un altro sito?
Se a duplicare o meglio, ad appropriarsi di contenuti altrui sono siti non autorizzati, anche se Google dovrebbe (in teoria) dare sempre priorità alla fonte originaria che si presume abbia maggior trust del sito duplicante (solitamente i siti detti “scaper” duplicano contenuti da decine di fonti e spesso i loro post vengono filtrati da Google automaticamente o sono soggetti a penalizzazioni Panda per “thin content”), è sempre bene contattare le fonti che duplicano contenuti e richiederne la rimozione dei contenuti.
L’alternativa è quella di richiedergli di impostare per ogni articolo, un link rel canonical che punta alla fonte originale e in questo modo le loro versioni non saranno indicizzate e non compariranno in serp.
Se “[SEO] Come riconoscere e gestire le duplicazioni di contenuti” ti è piaciuto, condividilo nei Social Network e potrai visualizzare un codice sconto per acquistare il pacchetto hosting PERSONAL con uno sconto del 40% sul prezzo di listino!
Visualizza le caratteristiche del pacchetto PERSONAL.



Lascia un commento